前言
自从 ChatGPT 上线以来,LLM (Large Language Model) 的热潮席卷了各行各业。Meta 开源的 LLaMA 模型给头部玩家进入这一领域提供了导航,Standford Alpaca 和 Microsoft LoRA 给小玩家们提供了低成本的玩法,总之只要想玩,人人可上手(PS. 老黄真的是秦始皇吃花椒 - 赢麻了,前有矿潮,后有AI,臭打游戏的能有几个钱,无足挂齿)。LLM 从刚开始的通用模型,到现在各个行业都在考虑垂直领域中的应用,网络安全领域当然也不例外。
发展背景
LLM 的崛起主要取决于3方面的因素:数据,算力,算法。
首先是数据方面,在信息爆炸的年代,加上元宇宙, WEB3 等概念的加持,数据上云,全民共享成为了时代的主流。在线社交网络,万物互联的物联网,移动互联网都为 LLM 提供了丰富的语料数据,Github 等代码托管平台提供了丰富的高质量代码数据……
然后是算力方面,归功于半导体行业的产业迭代带来的硬件支持,以及 NVIDIA 开启的 GPU 加速时代,老黄不遗余力发展的 CUDA,cuDNN 等配套软件支持。TensorFlow,Pytorch 为代表的 AI 框架降低了这一领域的门槛,同时也拉高了上限,以及 DeepSpeed 等并行计算框架带来的算力的成倍增长。
最后是算法方面,深度学习算法的迭代更新速度飞快,以 Transformer 为代表的算法框架逐渐突破了原来对深度网络结构的限制。
总之,现在的 LLM 崛起是量变引起质变的过程。
关键技术
2017年由 Google 团队提出的 Transformer 模型,是目前所有大语言模型的基础架构。
Attention is All You Need:Attention Is All You Need
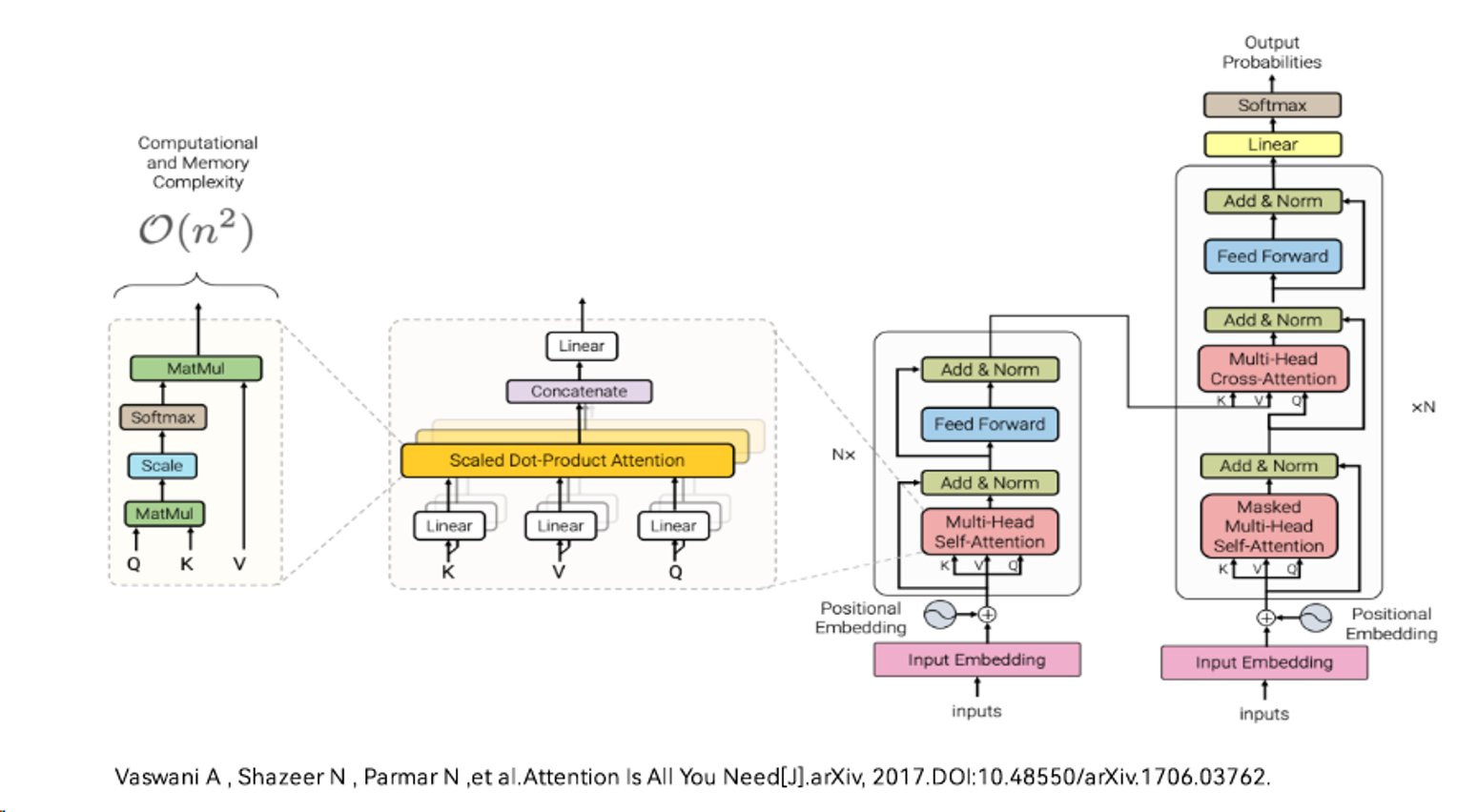
图中最右边的结构是论文中 Transformer 的内部结构图,左侧为 Encoder block,右侧为 Decoder block,Encoder 和 Decoder 都包含 6 个 block。红色圈中的部分为 Multi-Head Attention,是由多个 Self-Attention组成的,可以看到 Encoder block 包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention (其中有一个用到 Masked)。Multi-Head Attention 上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
图中最左边是 Self-Attention 的结构,在计算的时候需要用到矩阵Q(查询),K(键值),V(值)。在实际中,Self-Attention 接收的是输入(单词的表示向量x组成的矩阵X) 或者上一个 Encoder block 的输出。而Q,K,V正是通过 Self-Attention 的输入进行线性变换得到的。
图中左二 Multi-Head Attention 是由多个 Self-Attention 组合形成。
关于 Transformer 的更多细节介绍参考这里。
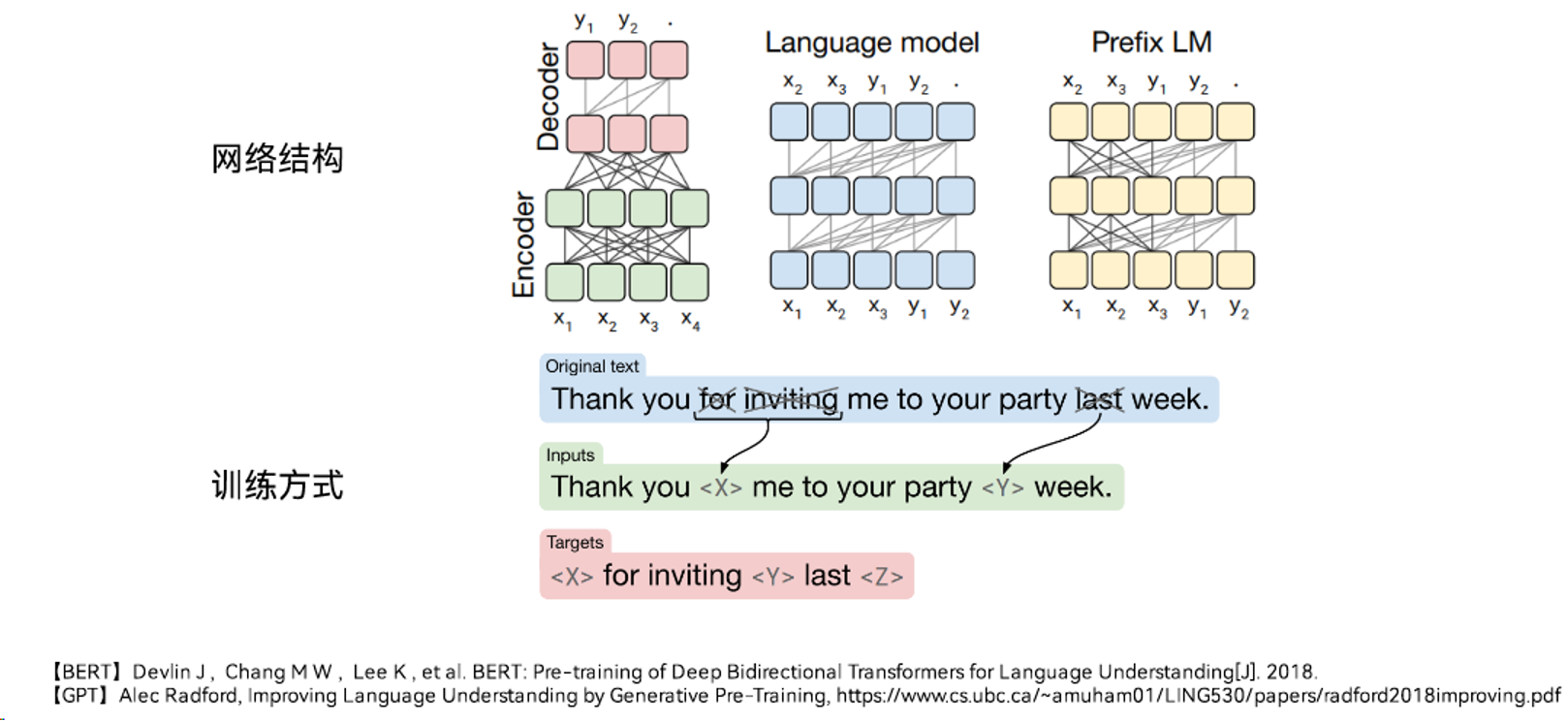
GPT 和 BERT都是基于 Transformer 的与训练语言模型,都是通过“预训练+微调”的模式完成下游任务的搭建。GPT是单向模型,只利用上文信息推断下文,而BERT是双向模型。GPT 基于自回归模型,可完成 NLU(Natural Language Understanding)和 NLG(Natural Language Generation)任务。原生 BERT 基于自编码模型,无法直接应用于文本生成任务。
发展历程
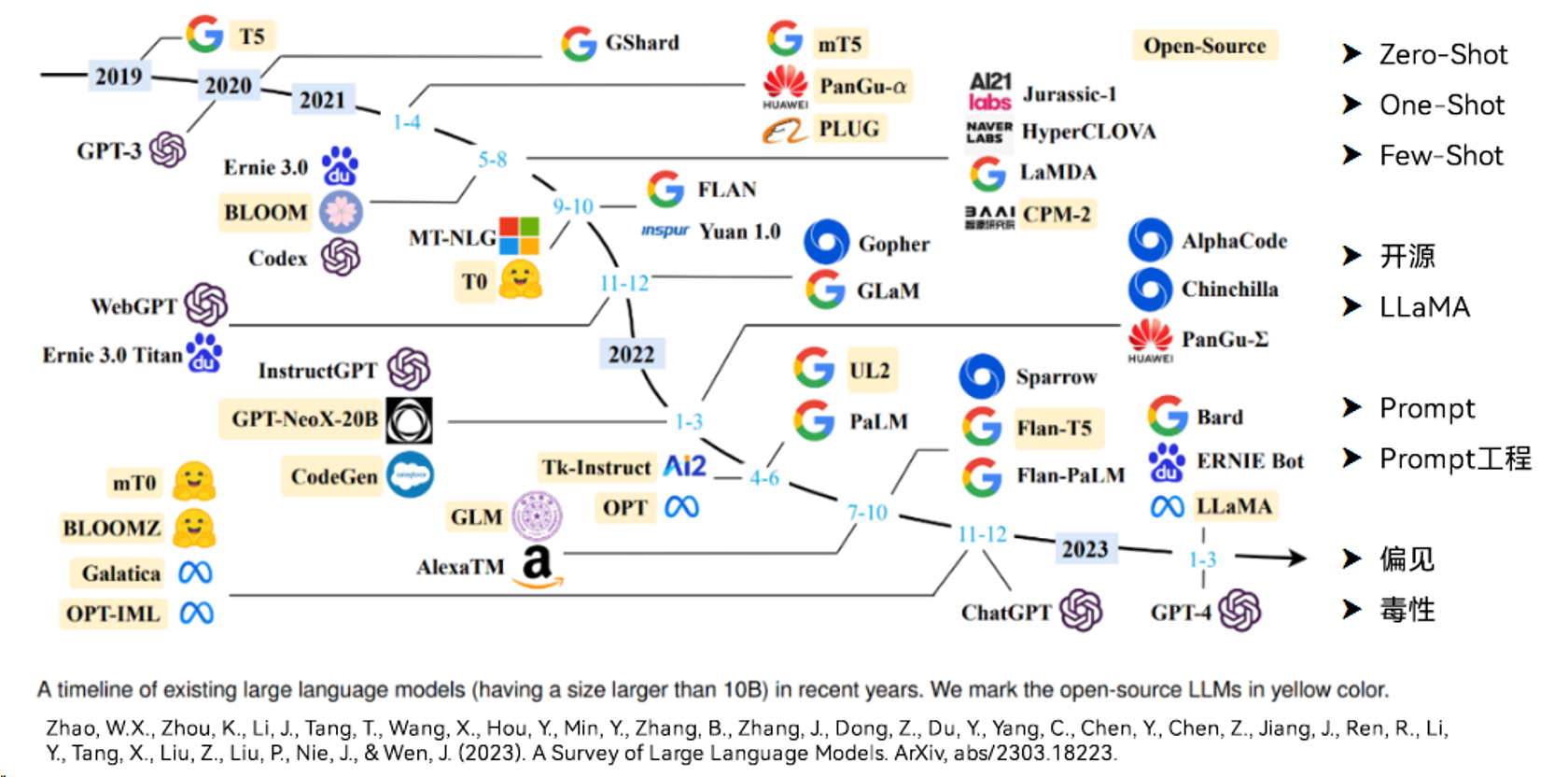
LLM 的发展经历了多年的积累,从单纯的 NLP 任务转变成为现在的多模态模型,也引申出了 Prompt 工程的概念,涉及到 AI Ethics 的内容也逐渐被重视。随着大语言模型的逐渐开源化和社区化,未来一定是越来越好的。
垂直领域
LLM 带来的变革深入各个产业,于是垂直领域的 LLM 越来越成为焦点。但是这里面临的主要问题是数据源,各个垂直领域有关数据的开放程度不尽相同。以网络安全领域为例,各家的安全数据不仅不可能共享,甚至公司内部也权限森明,导致了安全领域的 LLM 必然面临着数据源不充足的问题。
与此同时,LLM 对安全领域带来的冲击也是巨大的。
对于攻击方来说,攻击手段更为普及,高级攻击手段的门槛降低。通过 LLM 可以快速生成各种各样的高级混淆手段,定向的钓鱼邮件,钓鱼页面也可以通过 LLM 快速定制。攻击方的攻击速度也大大提升,绕过手法可以快速迭代,漏洞利用代码也能快速开发,1 Day 可能真的就是物理意义上的“1 Day”。
然而与之相对的防守方,LLM 加剧了与攻击方人员的能力、知识、技术的不对等,无法面对高级攻击常态化的趋势。防守方传统的防守手段高度依赖高水平的安全人员,然而现状却是安全人员的长期缺乏。同时防守方的自动化能力不足,迫切的需要机器对抗机器的手段。
构建流程
基本原理
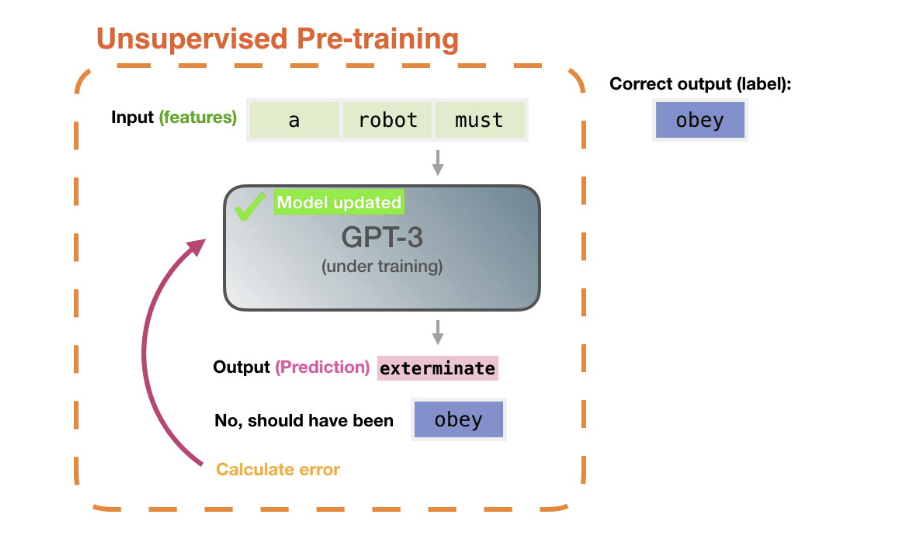
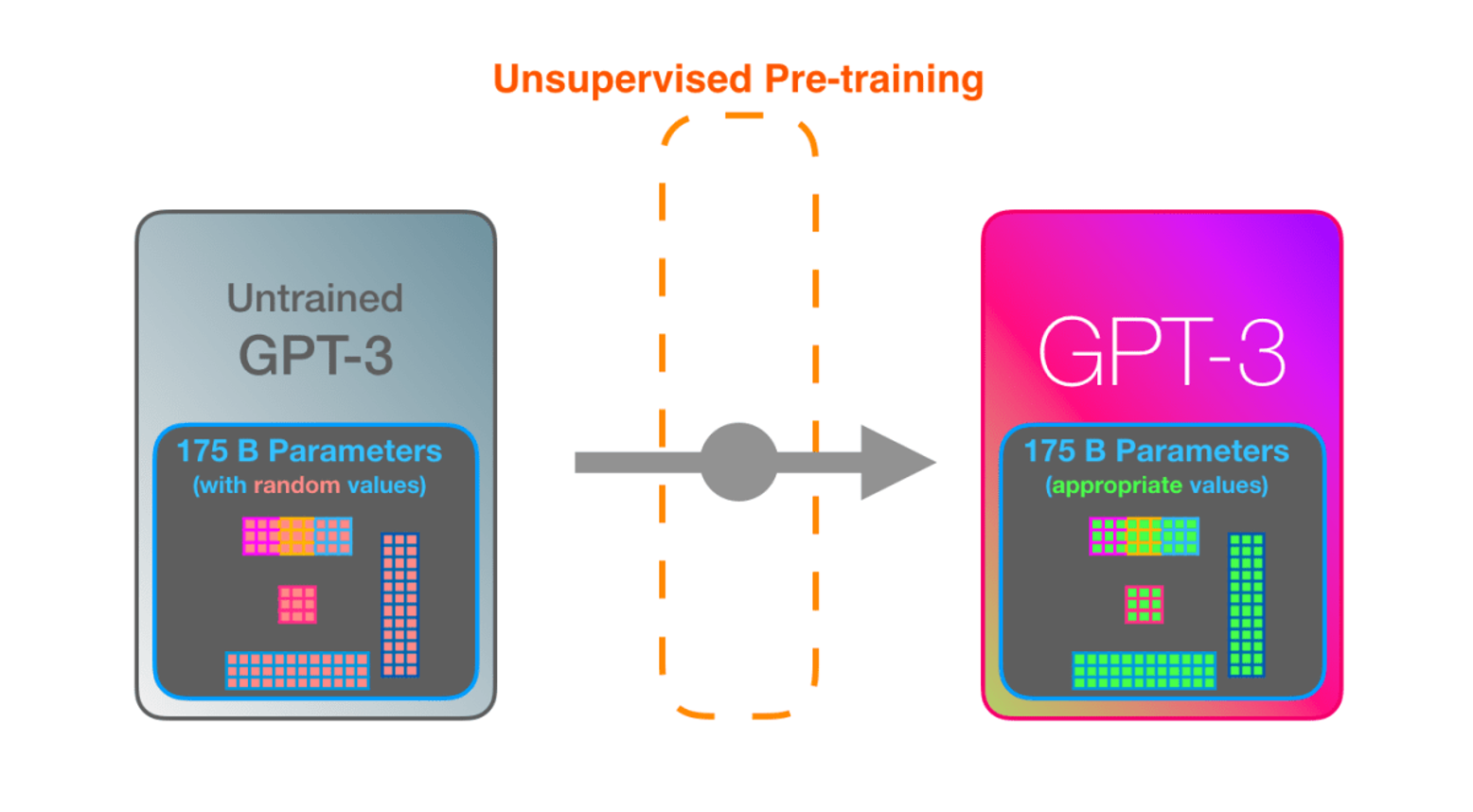
想要构建一个大语言模型,首先第一步是要预训练出一个初步的 NLP 模型,目的是通过给定的 Token, 能够预测下一个 Token。
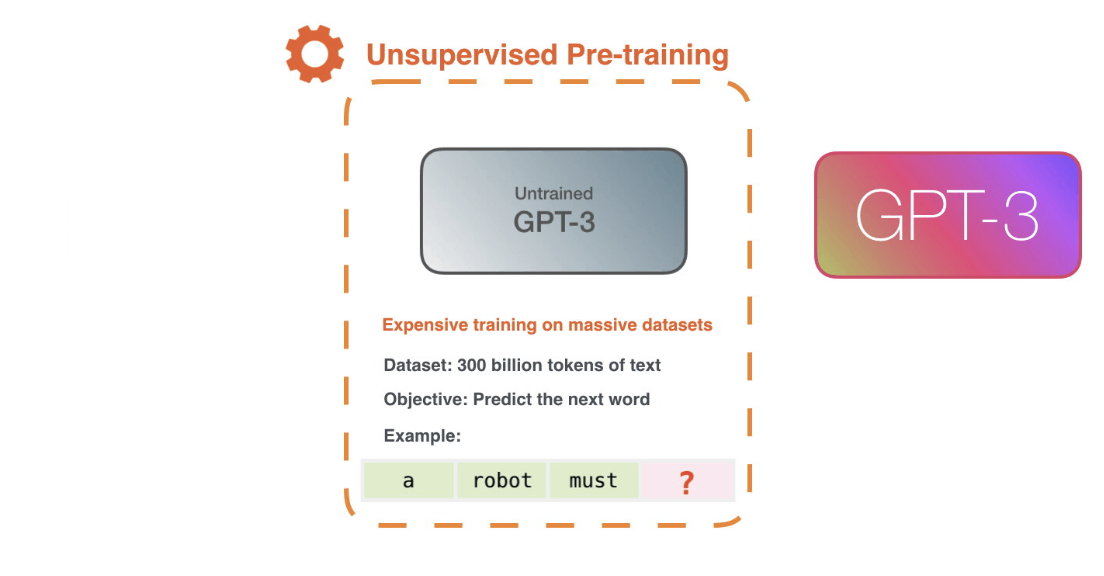
具体方式通过计算模型预测的下一个单词与真实的下一个单词之间的误差,通过算法获取降低误差的梯度,传播梯度更新模型参数。
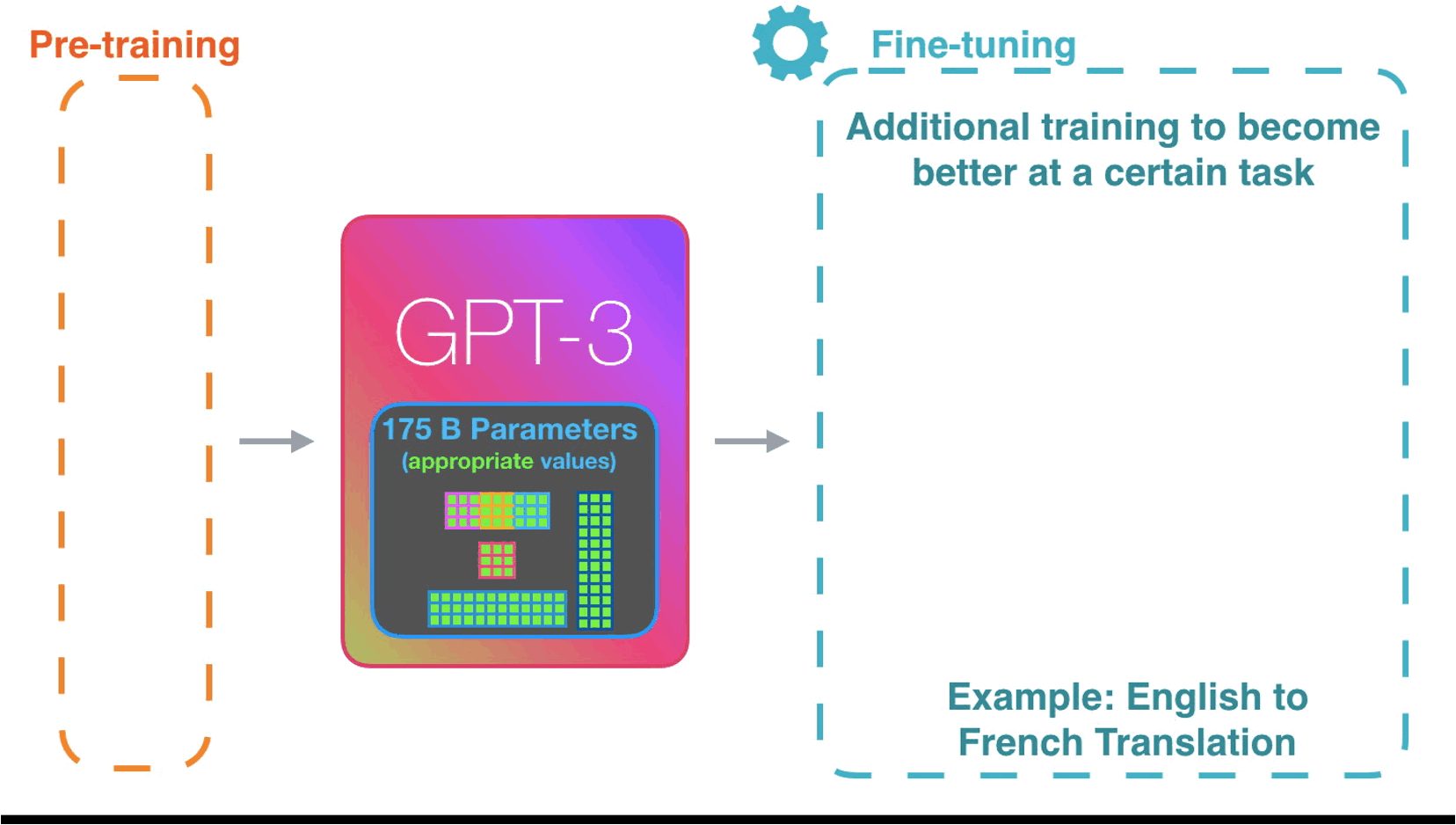
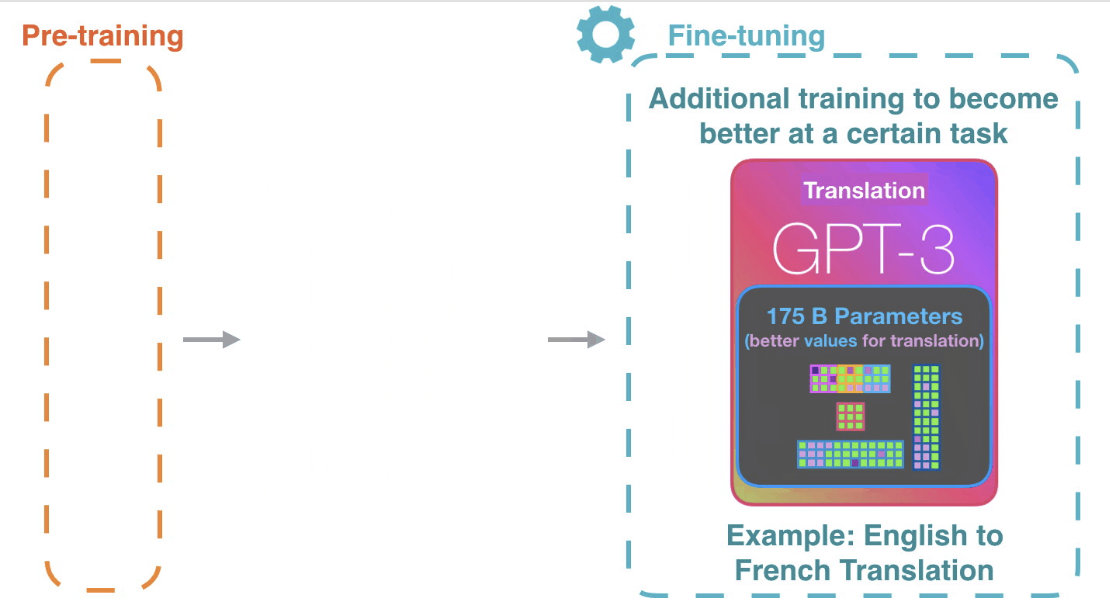
第二步是微调 Fine-Tune, 收集特定领域的数据,由该领域额专家对这些数据进行精心标注,通过上一步类似的训练手段,进一步更新模型的参数权重。
微调完成之后的模型就已经有了不错的变表现,可以部署推理了。输入一个句子,预测每个单词出现的频率,将频率最大的作为输出,循环往复,直到遇到终止符。

训练流程
一个完整 LLM 构建流程其实包含4步,除了前面说的预训练和微调之后,还需要通过奖励模型以及强化学习的手段进一步加强模型的能力。

建设方案
二次复现
Meta 放出的 LLaMA 模型基本做到了全开源,根据论文中的信息,LLaMA 的全部数据源均可获取,训练模型的超参数也基本公布,在模型结构上做的调整也详细列出,这就意味着 LLaMA 的结果完全可以复刻。
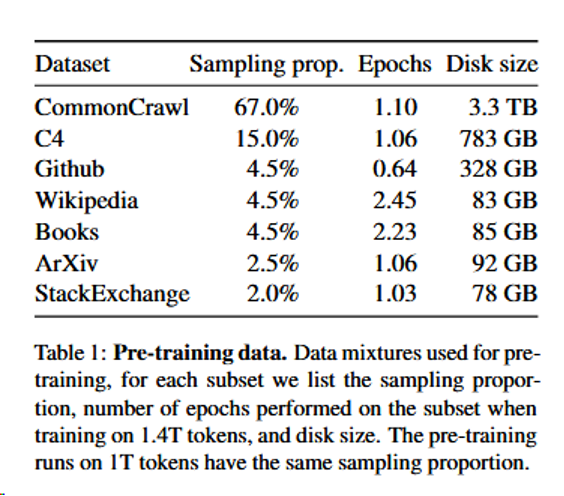
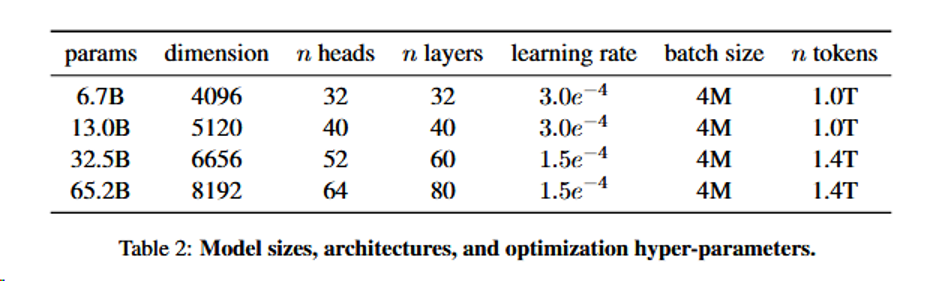

权重微调
对于财力和实力不够的玩家来说,微调是另一个可行的建设方案,无论是基于 LLaMA 还是 THUDM/GLM 模型的微调都能够在垂直领域有一定的效果。但是考虑到数据、基础语料以及模型权重的 License 等问题,想要有非常好的效果也是不现实的。
微调的方式目前有很多,比如 Stanford Alpaca、LoRA、P-Tuning v2 等。
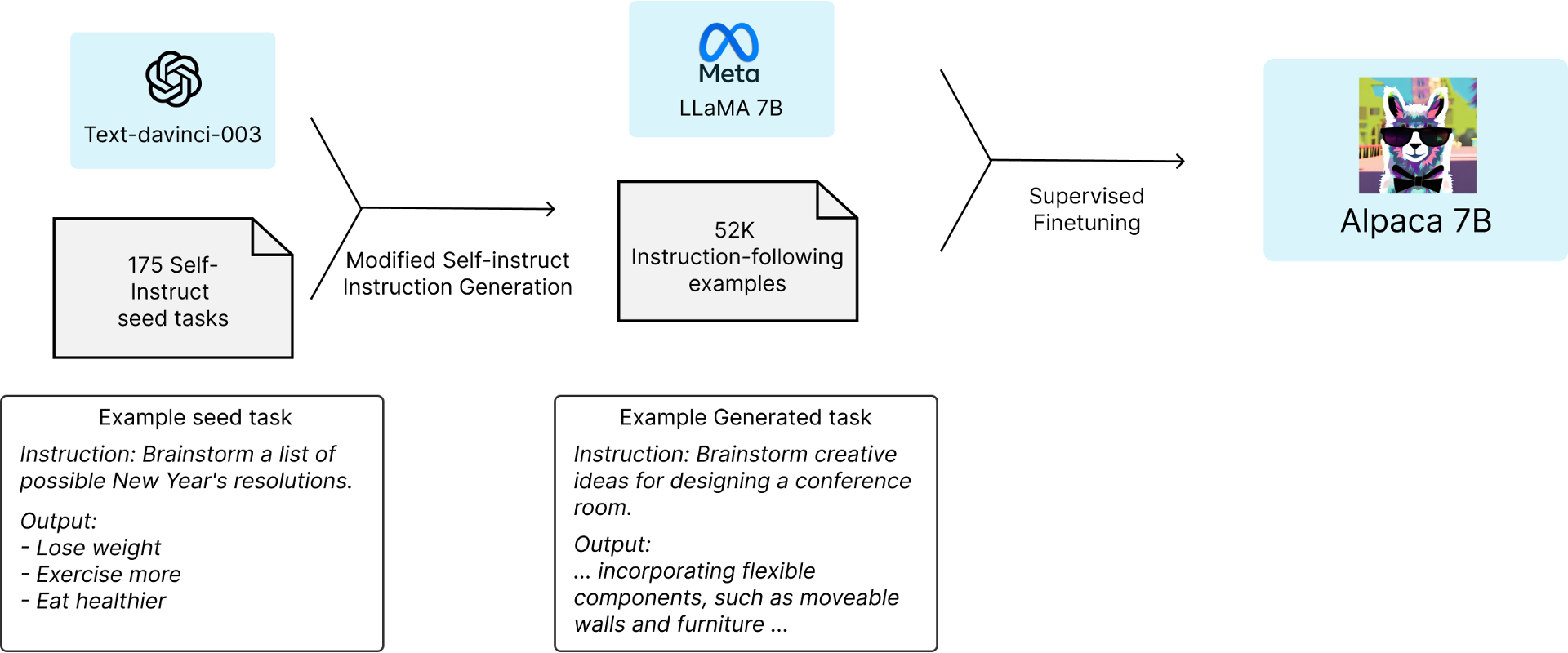
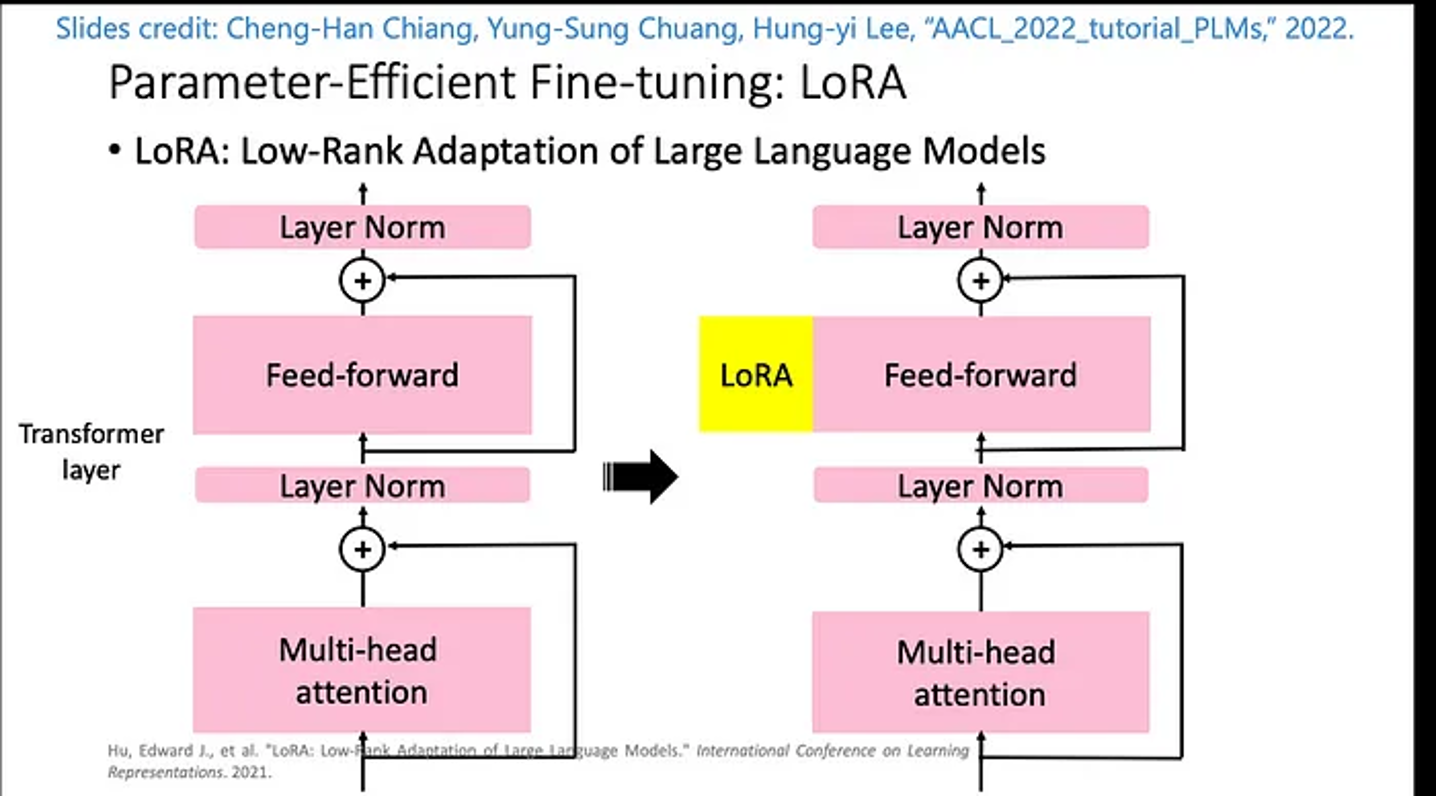
研究进展
项目推进
目前在推进的是 LLM 在安全领域的应用,覆盖两种建设方案。在权重微调方面,基于 LLaMA 模型,结合蜜罐数据,尝试将大语言模型作为蜜罐后台,模拟服务端的返回。此外也在尝试通过安全专家标注的网络攻击数据,训练 LLM 对网络攻击的检测能力,并提供判断思路。
由于目前开放的大模型都涉及到 License 问题,研究学习当然没问题,一旦从产品的角度考虑商用,就会收到权重的限制。所以需要重新进行预训练,调整模型的全部权重,其实也就是在做复现 LLaMA 的工作。
LangChain + LLM 的思路也很值得尝试。通过 LangChain 将本地的大量的威胁情报和 LLM 结合,制作本地知识库也是目前推动的方向。
发展方向
除了 Prompt 工程以外,培养模型的链式思维(Chain of Thoughts)也是热门方向。链式思维主要是培养模型的 Zero-Shot 能力,对于安全领域来说,这一方向的意义在于希望 LLM 能够在无样本的情况下检测 0 Day 攻击。
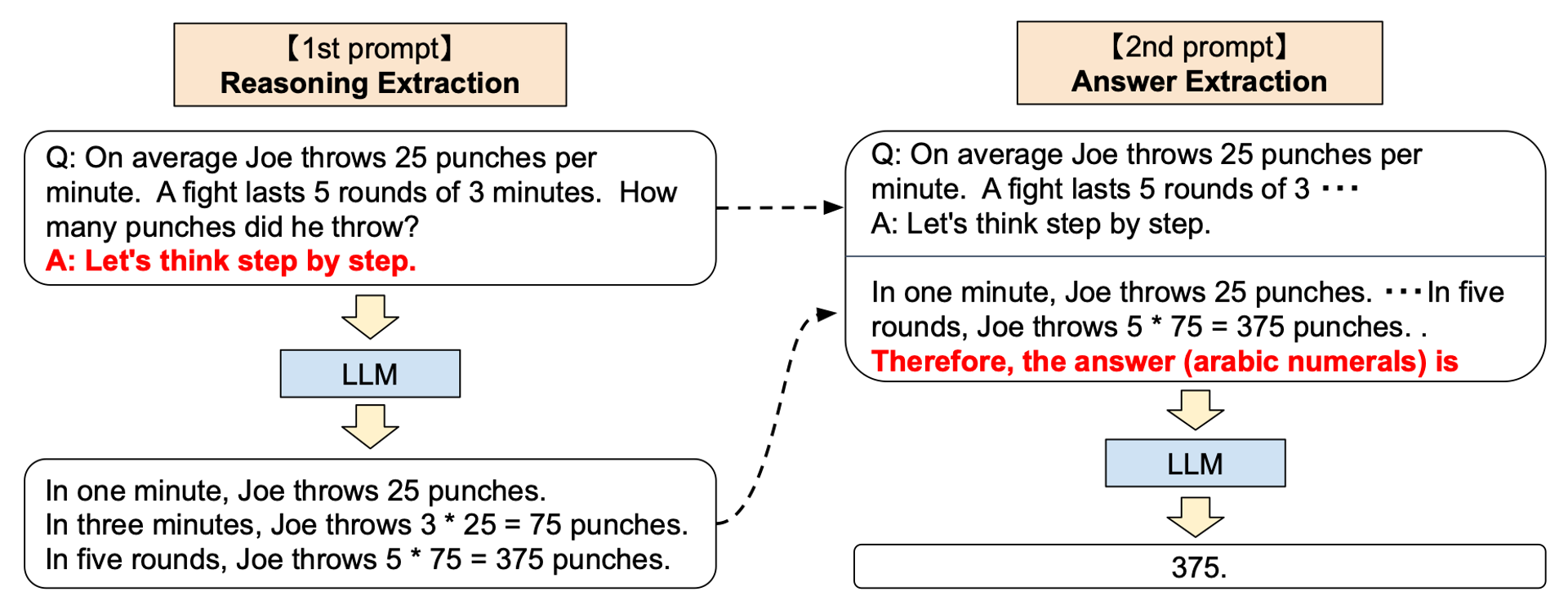
安全领域的 LLM 整体解决方案目前看来有两种。一种是将 LLM 作为分析中台,所有的数据通过 LLM 进行分析,通过其开放的 API 接口获取结果。另一种是将 LLM 作为调度中台以及人机交互接口,所有的安全数据由 LLM 调度分发,通过更简单快捷的小模型及其他分析引擎处理分析,分析结果整合成为一个统一的数据格式交由 LLM 与用户沟通,用更简单通俗的自然语言充当一个安全专家的形象。
虽然目前 LLM 还有很多问题,但是起码让我们看到了它的潜力,希望这是黎明前的那道曙光,身前一片坦途。