Info
- 名称:LLaMA: Open and Efficient Foundation Language Models
- 作者:Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet Marie-Anne Lachaux, Timothee Lacroix, Baptiste Rozière, Naman Goyal Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin Edouard Grave, Guillaume Lample - Meta AI
- 原文链接:LLaMA: Open and Efficient Foundation Language Models
Intro
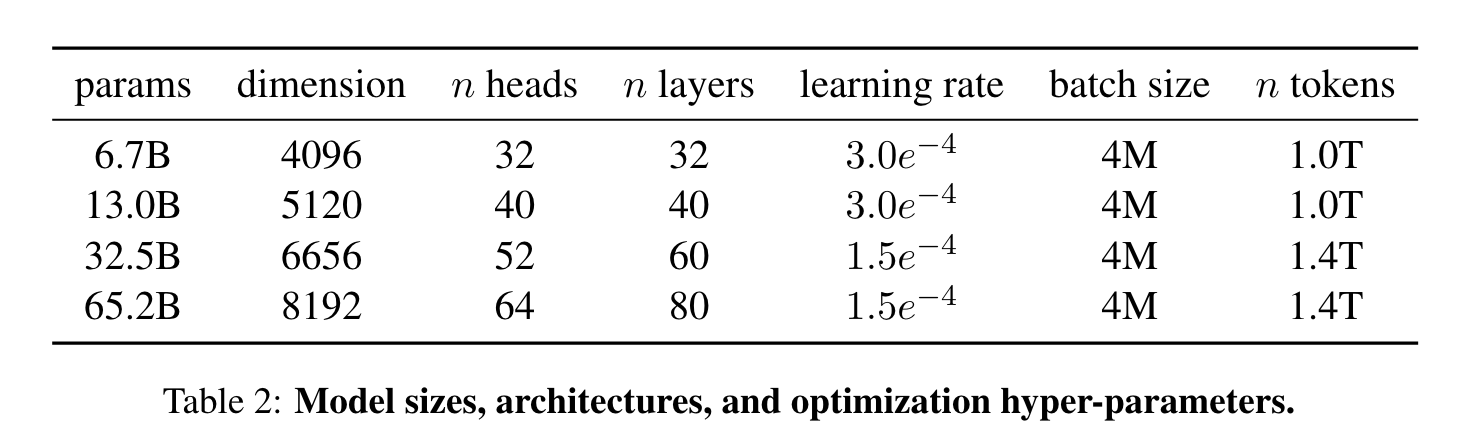
- 训练了一系列的语言模型在不同的推断预算上实现最佳表现,模型参数从7B到65B不等。其中,13B模型大多数 benchmarks 表现超越 GPT-3,规模只有 GPT-3 的十分之一。65B模型能够和最大最好的语言模型 Chinchilla 或 PaLM-540B 竞争。
- 65B模型在2048张A100(80GB RAM)的集群,包含1.4T tokens的数据集情况下,训练时间为约为21天。
Contributions
- 通过多头注意力(Multi-head attention)机制减少内存使用以及运行时间。具体实现为不存储 attention 权重,不计算 key/query 的分数。
- 为了提升训练效率,减少了 backword pass 过程中重新计算 avtivations 的数量。更准确的说,保存了很难计算的 activations,比如线性层的输出。实际是通过手动实现 transformer 层的 backward 功能函数,而不是依赖于 PyTorch 提供的 autograd 方法。
- 尽可能多的重叠 activations 以及 GPU 之间通过网络的交流两部分产生计算(通过 all_reduce 操作)。
Paragraph
Pre-training Data
- English CommonCrawl:通过 fastText 线性分类器预处理了 CCNet pipeline【1】获取的数据,去除了非英语页面,并通过一个 n-gram 语言模型过滤掉了低质量内容。
- C4:公开可获取的数据集,同样包含去重和语言识别等预处理过程。
- Github:在 Google BigQuery 上可公开获取的公共 Github 数据集。
- Wikipedia:覆盖20种语言,去除了超链接,评论和其他格式化的内容。
- Gutenberg and Books3:从书籍层面去重,转化为数据集。
- ArXiv:去除第一节之前的部分,引用,评论,行内扩展的定义等作为科研类数据集。
- Stack Exchange:高质量的问答类数据,覆盖多元领域。
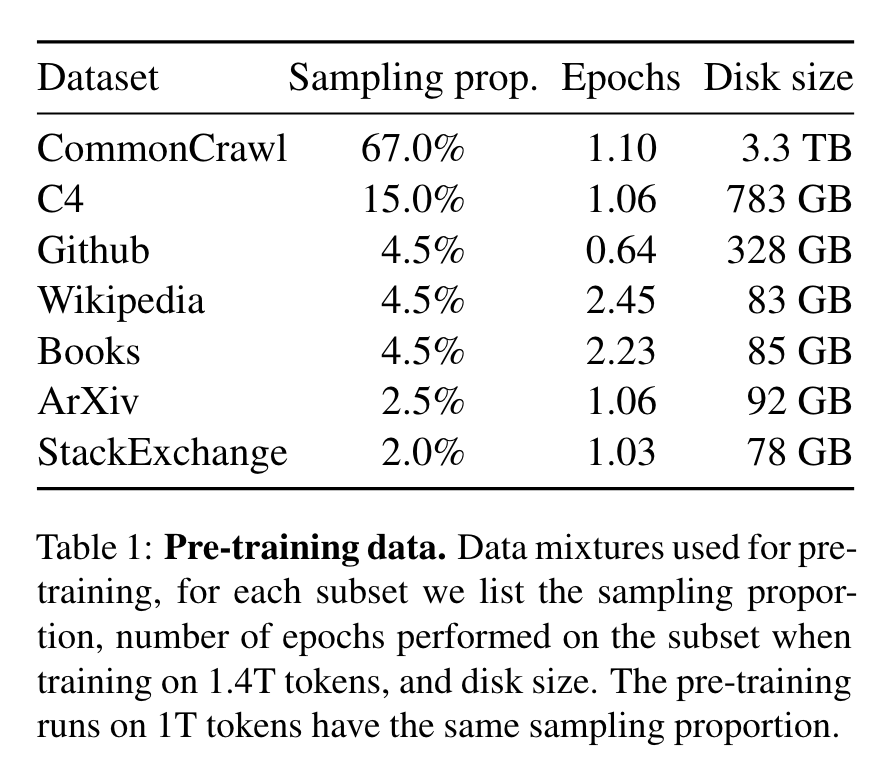
分词器(Tokenizer)基于 bytepair encoding(BPE)算法【2】,具体实现参考 SentencePiece【3】。处理完成之后,整体数据集大约包含1.4T tokens。除了 Wikipedia 和 Books 的数据运行了大约 2 轮之外,其他数据只使用一次。
Network
- 神经网络基于 transformer architecture【4】,改进点如下:
- Pre-normalization [GPT3]:每一个 transformer sub-layer,通过 RMSNorm 归一化函数【5】归一化输入而不是输出。
- SwiGLU activation function [PaLM]:用 SwiGLU 激活函数【6】替换 ReLU。PaLM 中维度数据使用(2/3)4d而非4d。
- Rotary Embeddings [GPTNeo]:移除绝对位置嵌入(absolute positional embeddings),加入 rotary positional embeddings(RoPE)【7】。
Optimizer
- Optimizer 使用 the AdamW optimizer【8】,超参数 β1 = 0.9,β2 = 0.95。最终学习速率是最大学习速率的10%。weight decay 为 0.1,gradient clipping 为 1.0,warmup steps 为 2000。
- 优化的具体实现可通过 xformers库。
Comments
- 以更小的模型体积实现更好的性能,降低了大语言模型实用场景的门槛。
- 技术特点均有提及,训练集均可获得,过程复现的可能性大,但仍需要进一步研究。
- Finetuning 的过程及技术未提及。
References
Guillaume Wenzek, Marie-Anne Lachaux, Alexis Conneau, Vishrav Chaudhary, Francisco Guzmán, Armand Joulin, and Edouard Grave. 2020. CCNet: Extracting high quality monolingual datasets from web crawl data. In Language Resources and Evaluation Conference.
CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data
Rico Sennrich, Barry Haddow, and Alexandra Birch. 2015. Neural machine translation of rare words with subword units. arXiv preprint arXiv:1508.07909.
Taku Kudo and John Richardson. 2018. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. arXiv preprint arXiv:1808.06226.
SentencePiece: A simple and language independent subword tokenizer…
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems 30, pages 5998–6008.
Biao Zhang and Rico Sennrich. 2019. Root mean square layer normalization. Advances in Neural Information Processing Systems, 32.
Noam Shazeer. 2020. Glu variants improve transformer. arXiv preprint arXiv:2002.05202.
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. 2021. Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:2104.09864.
RoFormer: Enhanced Transformer with Rotary Position Embedding
lya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101.