Info
- 名称:GLM: General Language Model Pre-training with Autoregressive Blank Infilling
- 作者:
- Zhengxiao Du:Tsinghua University,Beijing Academy of Artificial Intelligence (BAAI)
- Yujie Qian:MIT CSAIL
- Xiao Liu:Tsinghua University,Beijing Academy of Artificial Intelligence (BAAI)
- Ming Ding:Tsinghua University,Beijing Academy of Artificial Intelligence (BAAI)
- Jiezhong Qi:Tsinghua University,Beijing Academy of Artificial Intelligence (BAAI)
- Zhilin Yang:Tsinghua University,Shanghai Qi Zhi Institute
- Jie Tang:Tsinghua University,Beijing Academy of Artificial Intelligence (BAAI)
- 原文链接:arxiv
Intro
- 现有的预训练框架无法灵活的应对所有NLP任务,本文提出基于自回归 + 空白填充(blank infilling)的预训练模型GLM(General Language Model)应对NLU(Natural Language Understanding)任务以及文本生成任务。
Contributions
- 结合AR(autoregressive)模型和空白填充(blank infilling)技术,提出GLM预训练框架应对NLU和长文本生成为主的多种NLP任务。
- 在原来空白填充基础上提出了两个创新,span shuffling 和 2D positional encoding。
Paragraph
Sec.1
- 现有的预训练框架可以分为三类
- 自回归(autoregressive)模型:如GPT[1],在长文本生成方面很成功,但是无法完全捕捉上下文之间的依赖关系。
- 自编码(autoencoding)模型:如BERT[2],适合NLP任务,但是不能直接应用于文本生成。
- 编码器-解码器模型:如T5[3],统一了NLU和条件生成,但是需要更多的参数匹配基于BERT模型的性能表现。
Sec.2
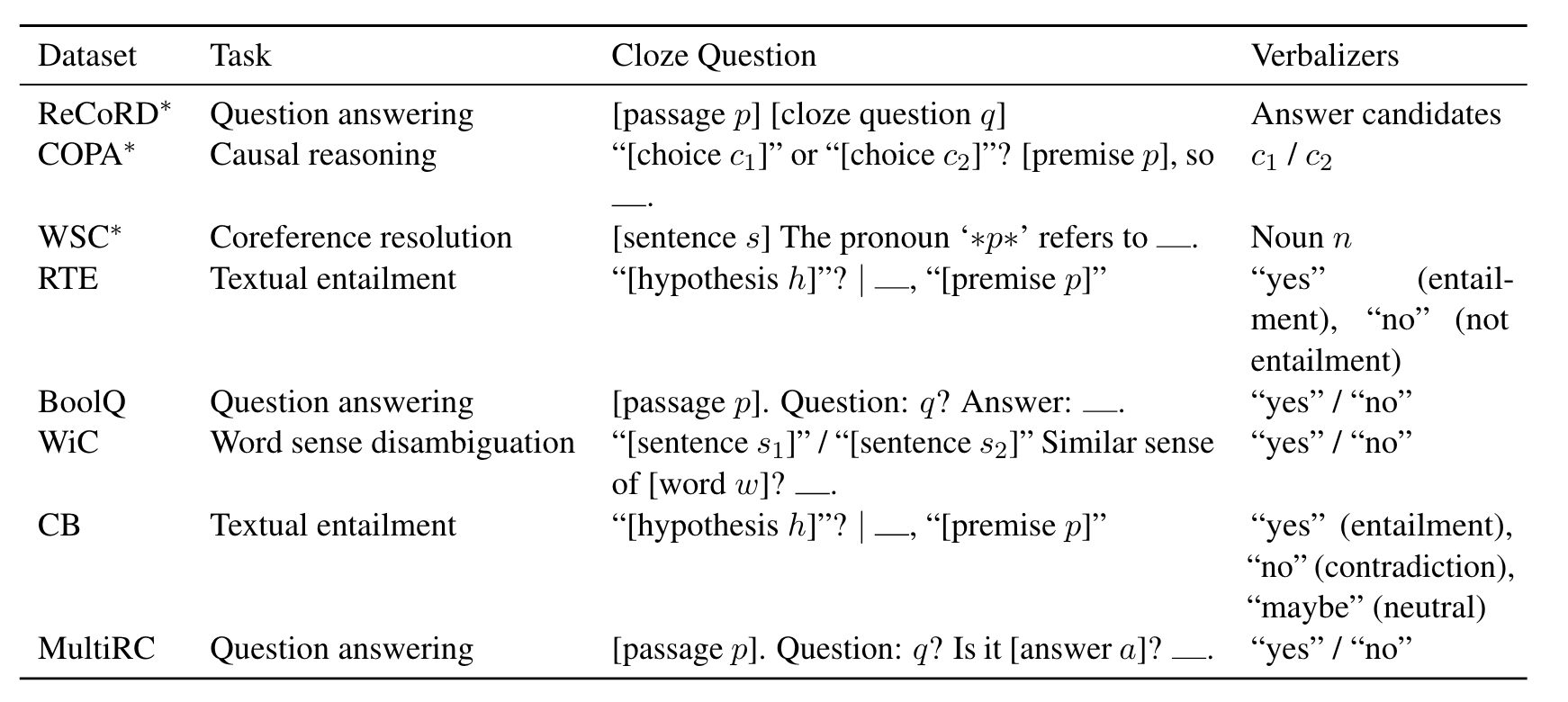
- GLM 预训练:输入的部分被分为两个部分。A部分是被破坏的文本
Xcorrupt,B部分为被sample的部分。B部分中每个span前后分别加上[S]和[E],训练目标是预测B部分。使用两种位置向量作为输入。Self-attention的mask部分控制attend的位置,蓝色部分即A部分只能attend本身,黄色和绿色部分也即B部分能attend整个A部分以及前面已经生成的部分。

- 多任务预训练:
- 文档级:对单一span取样,长度为原长度均匀分布中的50% - 100%。这一部分旨在长文本生成。
- 句子级:限制被mask的span必须是完整句子,取样覆盖15%的原始tokens。这部分旨在预测完成句子和段落的seq2seq任务。
- GLM使用的是单一Transformer以及一些改进
- 重新排列了层的归一化和残差连接的顺序。
- 使用单一的线性层用于输出token的预测。
- 用GeLUs替代ReLU作为激活函数[4]。
- 2D Positional Encoding: 每一个token由两个位置编码组成
- 第一个位置编码为token在
Xcorrucpt中的位置。被mask的token为【MASK】标志的位置。 - 第二个位置编码代表其在intra-span中的位置。Part A的token该位置编码为0, Part B的token该位置编码从1到span的长度。
- 第一个位置编码为token在
Sec.3
- Finetuning GLM(调优)
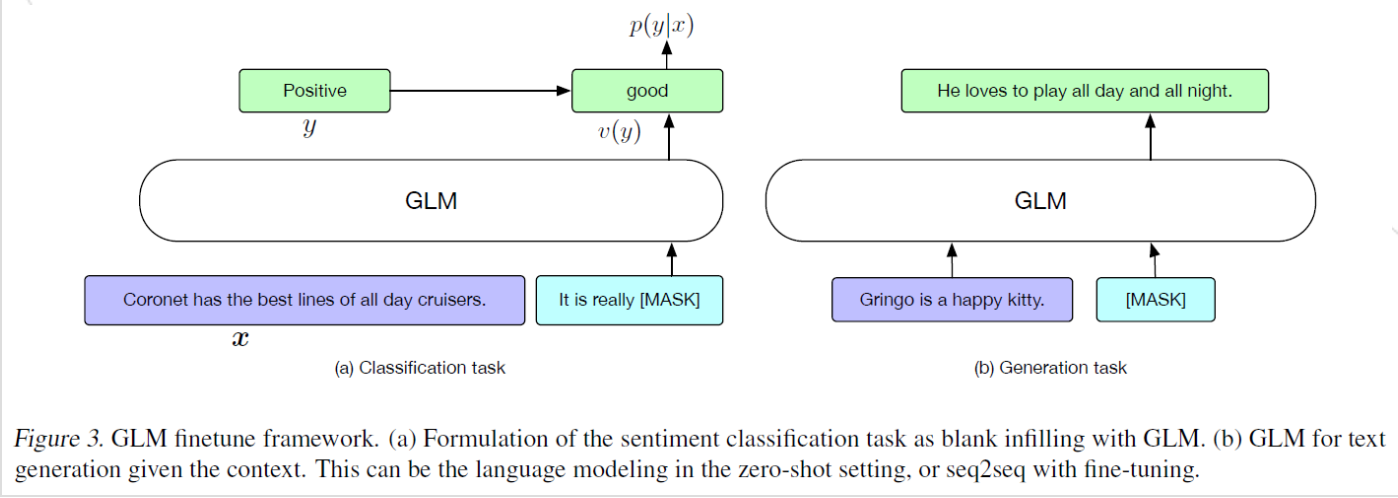
- 分类任务(NLU):参考PET[5],对于带标签的例子(x,y),将输入 x 转化成为一个包含单一【MASK】的填空题,预测标签 y 映射到这个填空题的答案集中。通过交叉熵(cross-entropy loss)来微调模型。
- 文本生成任务:给定的上下文构成输入的A部分,在结尾append一个【MASK】token,以autoregressive模型生成B部分。
Comments
- 提出了改进型的GLM模型旨在同时适配NLU和长文本生成任务,结合了span shuffling 和 2D positional encoding两处创新。
- 分类任务介绍不够详细,详细方法可能需要通过代码实现来佐证。
References
- Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018a. Improving Language Understanding by Generative Pre-Training.
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In NAACL 2019, pages 4171–4186.
- Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the Limits of Transfer Learning with a Unified Text-toText Transformer. J. Mach. Learn. Res., 21:140:1140:67.
- Dan Hendrycks and Kevin Gimpel. 2016. Bridging nonlinearities and stochastic regularizers with gaussian error linear units. CoRR, abs/1606.08415.
- Timo Schick and Hinrich Schütze. 2020a. Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference. pages 255–269.
Related Materials